|
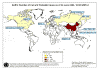 Figure 3
Figure 3
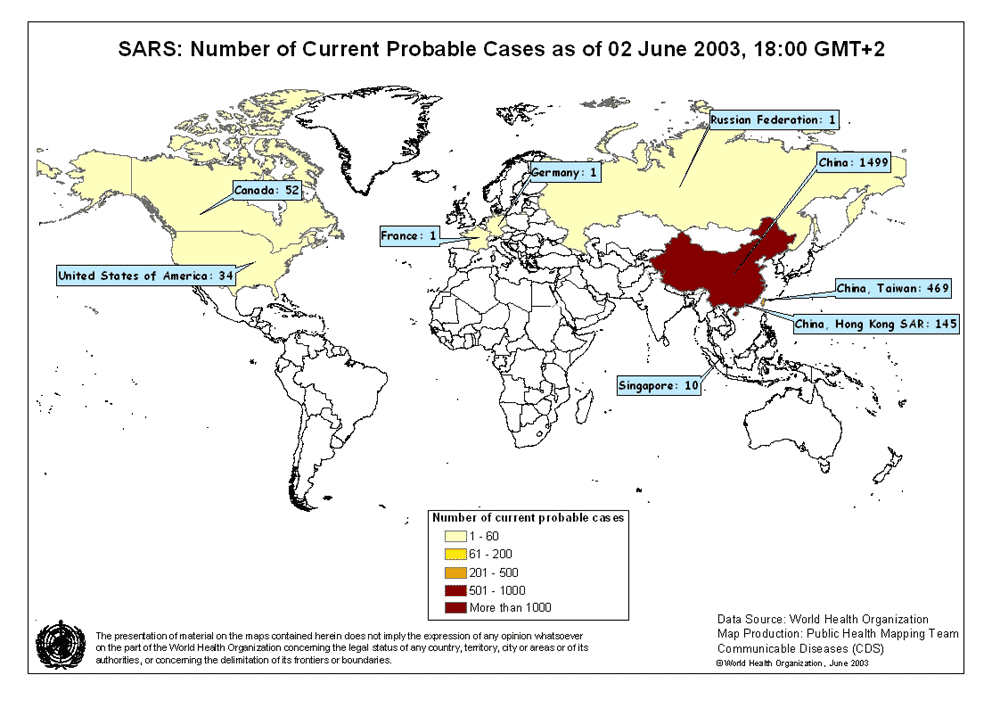
Map of probable SARS cases. June 02, 2003
WHO
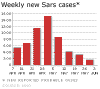 Figure 4
Figure 4
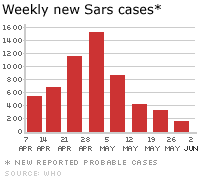
.Weekly new cases of SARS
©
WHO/BBC
 Figure 8.
Figure 8.
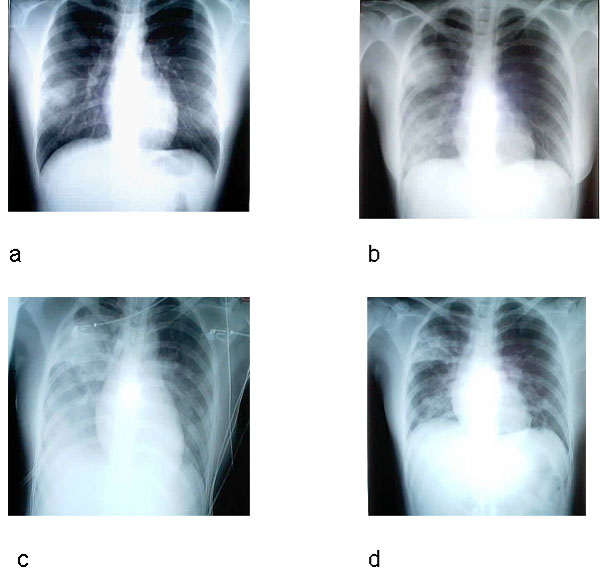
Chest radiographs of index patient with severe acute
respiratory syndrome (SARS). a, day 5 of symptoms; b, day 10; c, day 13;
d, day 15.
Li-Yang Hsu, Cheng-Chuan Lee, Justin A. Green, Brenda Ang, Nicholas I.
Paton, Lawrence Lee, Jorge S. Villacian, Poh-Lian Lim, Arul Earnest, and
Yee-Sin Leo -
Tan Tock Seng Hospital, Tan Tock Seng, Singapore. Emerging
and Infectious Diseases
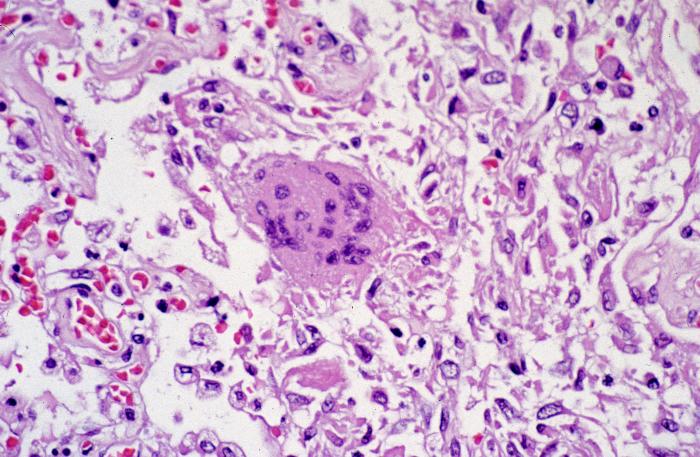
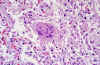 Figure 9 Pathologic
cytoarchitectural changes indicative of diffuse alveolar damage, as well
as a multinucleated giant cell with no conspicuous viral inclusions.
Figure 9 Pathologic
cytoarchitectural changes indicative of diffuse alveolar damage, as well
as a multinucleated giant cell with no conspicuous viral inclusions.
CDC/Dr. Sherif
Zaki
|
SEVERE ACUTE RESPIRATORY SYNDROME (SARS)
In late 2002, a new syndrome was observed in
southern China (Guangdong Province). It was named Severe Acute
Respiratory Syndrome (SARS). This disease, which has now been reported
in Asia, North America, and Europe (figure 3), is characterized by a fever
above 38 degrees (100.4 degrees Fahrenheit) accompanied by headache,
general malaise and aches. Respiratory symptoms are initially usually
mild but after a few days to one week, the patient may develop a dry
non-productive cough and breathing may become difficult (dyspnea).
Respiratory distress leads to death in 3-30% of cases. Laboratory tests
show a reduction in lymphocyte numbers and a rise in serum
aminotransferase activity which indicates damage to the liver.
The initial outbreak of SARS peaked in April 2003
and by June had tailed off (figure 4). By that time, there had been about
8,000 cases worldwide and 775 deaths. In addition, there were
billions of dollars in economic losses.
Virus from infected patients was grown on monkey
Vero E6 cells in tissue culture and identified as a new coronavirus (SARS-CoV). It has a genome of 29,727
bases and eleven open reading frames. The organization of the genome is
very similar to that of other coronaviruses (5’ replicase (rep), spike
(S), envelope (E), membrane (M), nucleocapsid (N)-3′
and short untranslated regions at both termini). The replicase (RNA
polymerase) gene
occupies the 5’ two-thirds of the genome and has, like other
coronaviruses, two overlapping open reading frames. It also codes for a
protease that is part of the RNA polymerase polyprotein. There are nine
possible open reading frames that are not found in other coronaviruses
and may code for proteins that are unique to the SARS virus. Using
antibody tests, SARS-coronavirus has been associated with SARS cases
throughout the world.
Diagnosis
The Centers for Disease Control recommend a chest
radiograph (figure 8), pulse oximetry (a test used to measure the
oxygen saturation of the blood), blood cultures, sputum Gram's stain
and culture, and testing for other viral respiratory pathogens, notably
influenza A and B and respiratory syncytial virus. A specimen for
Legionella and pneumococcal urinary antigen testing should also
be considered. People with suspected SARS should be isolated and
quarantined.
Infection by SARS-CoV-1 shows changes
indicative of diffuse alveolar damage, as well as a multinucleated
giant cell with no conspicuous viral inclusions (figure 9).
Treatment
There is no agreed treatment for SARS other than
management of symptoms. Drugs are under development and of
particular interest are drugs that may block the protease function
since this is crucial to the virus. There is no approved vaccine against the SARS virus
although some have been developed. Veterinary vaccination
programs of modest success exist for a number of economically
important coronaviruses.
|
|
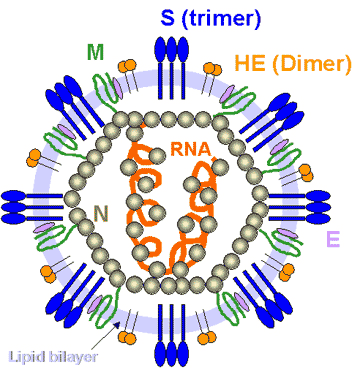
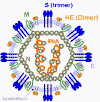 Figure
10 Coronavirus structure. Adapted from Lai and Homes. In
Fields' Virology. Lippencott Figure
10 Coronavirus structure. Adapted from Lai and Homes. In
Fields' Virology. Lippencott
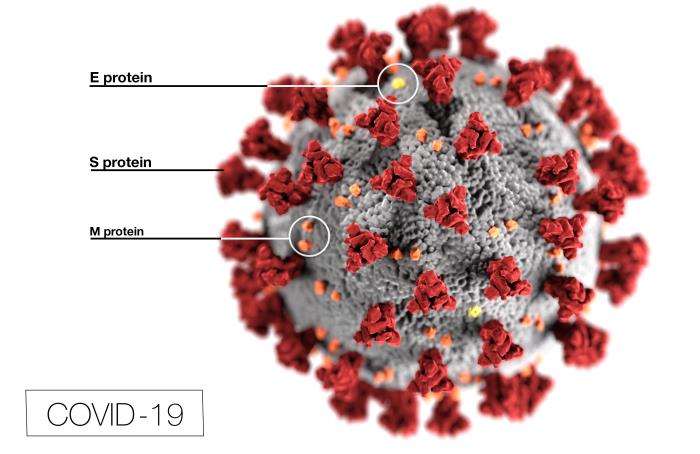
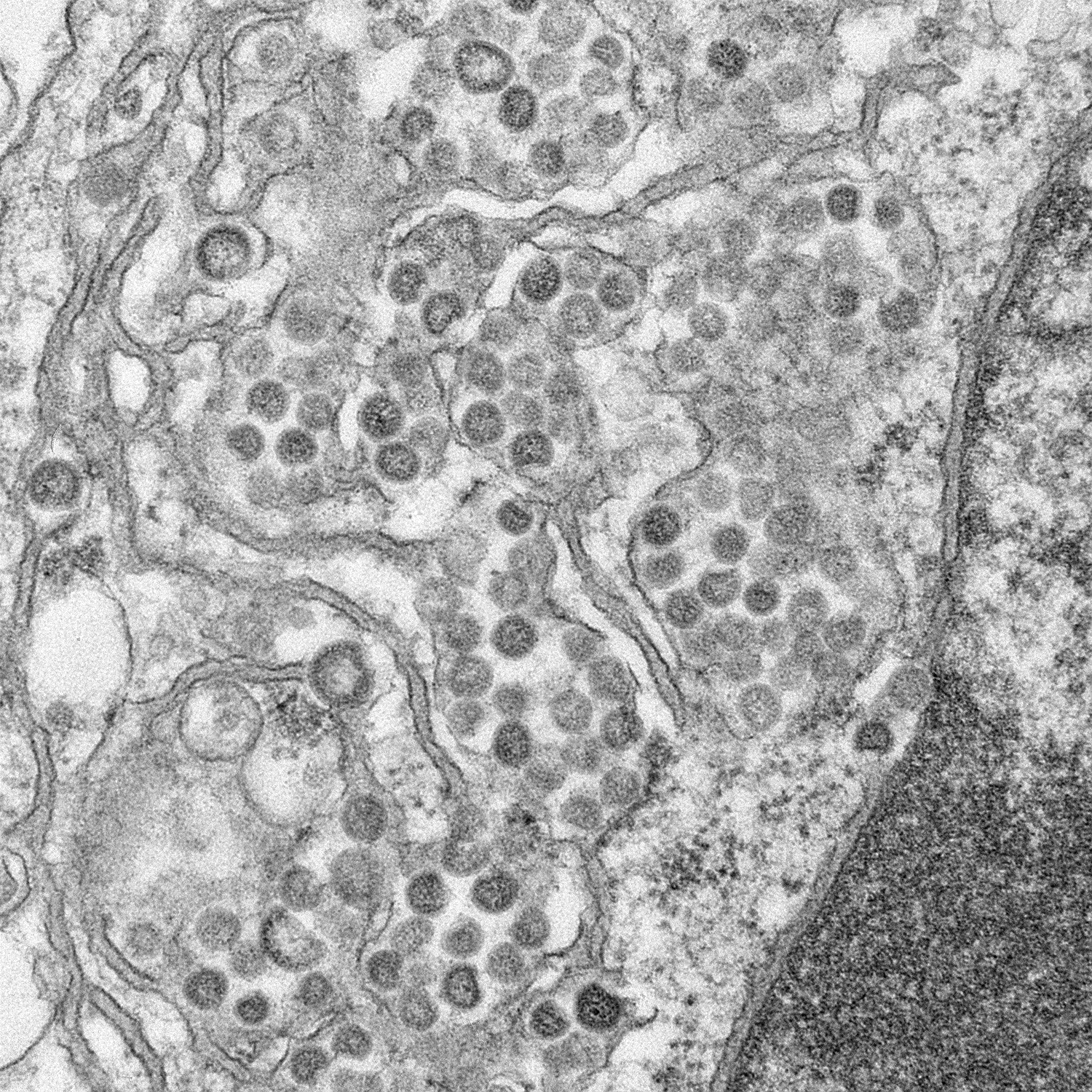
 Figure 11
Figure 11
Ultrastructural morphology of a coronavirus viewed by electron
microscopy. The spikes (S protein) give the appearance of a crown, hence
the name. The E and M proteins are also located on the outer surface of
the virus.
CDC
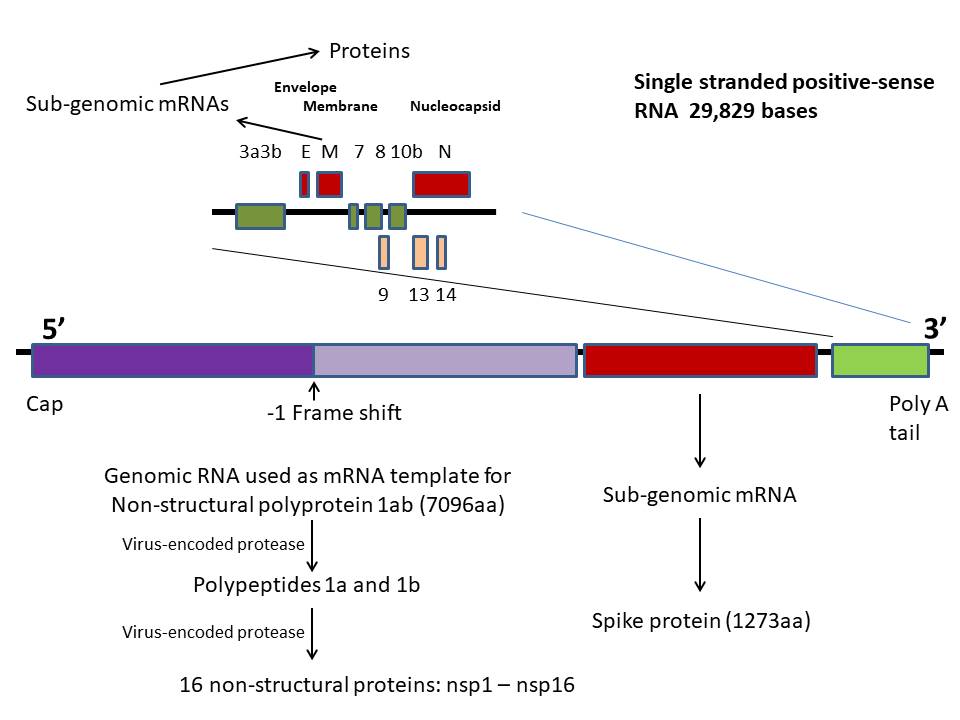
 Figure 12
Figure 12
SARS-CoV-2 genome showing the order of the genes and the proteins
encoded by them
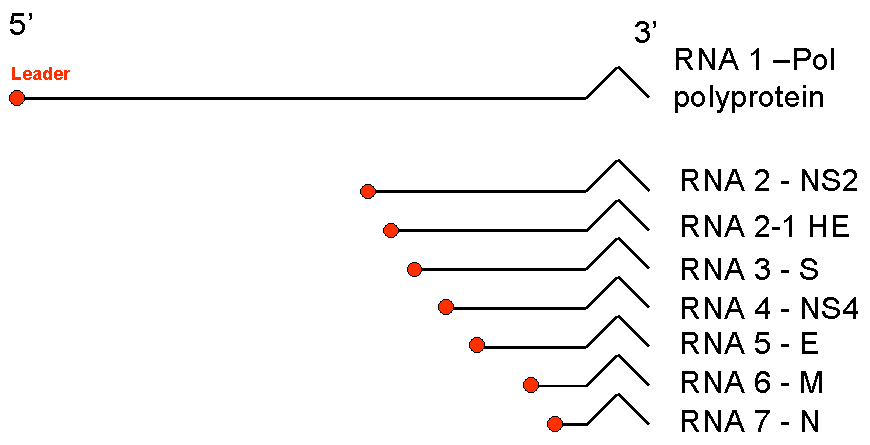
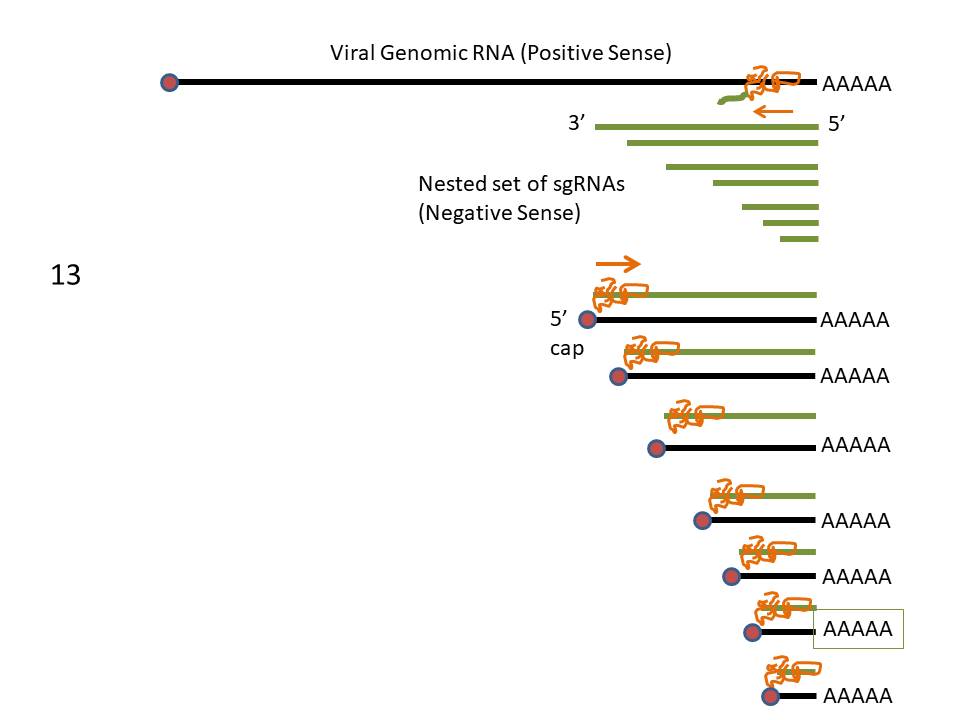
 Figure
13 Messenger RNAs of corona viruses. A nested set of RNAs with a
common 3' end are formed. The mRNA for the polymerase (pol) is the same
length as the genomic RNA. The remainder are truncated at the 5' end
although all have a common leader sequence Figure
13 Messenger RNAs of corona viruses. A nested set of RNAs with a
common 3' end are formed. The mRNA for the polymerase (pol) is the same
length as the genomic RNA. The remainder are truncated at the 5' end
although all have a common leader sequence |
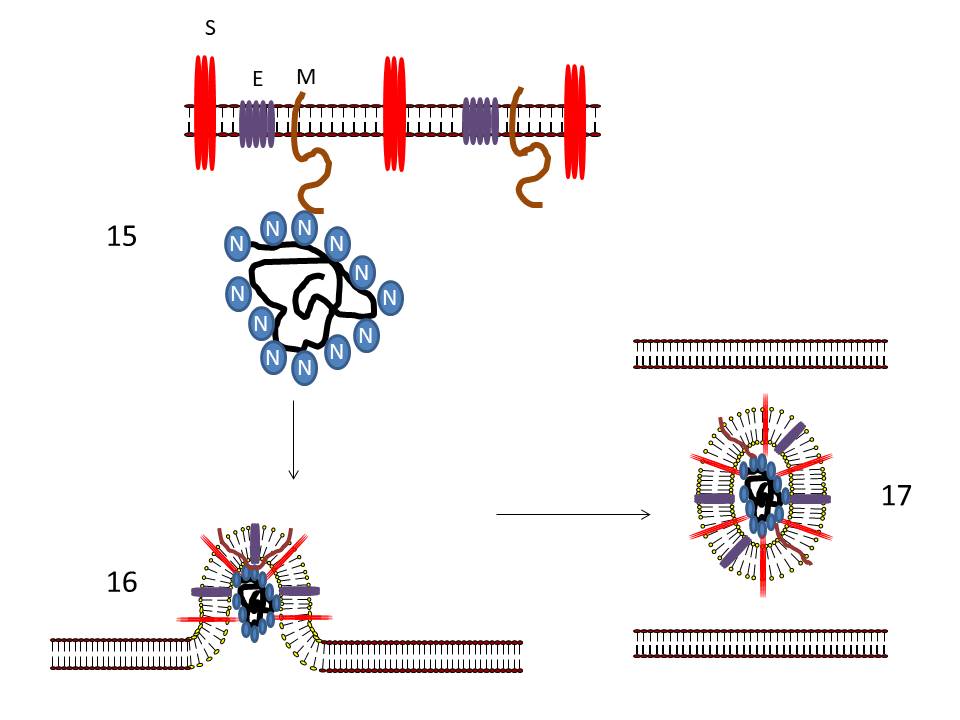
CORONAVIRUS STRUCTURE
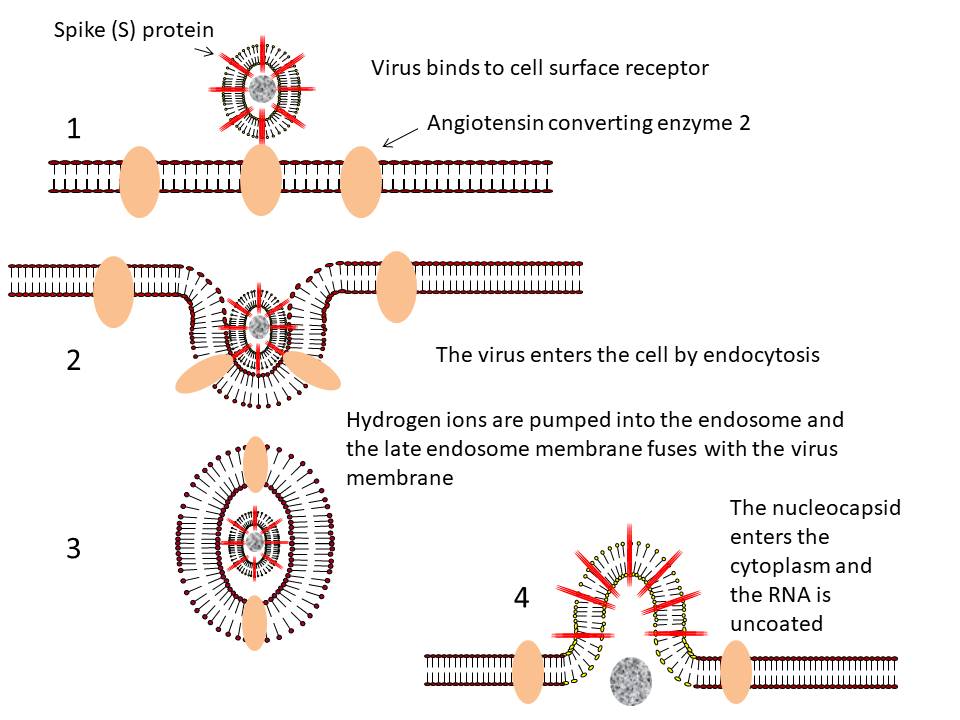
Coronaviruses are positive-sense single strand RNA
viruses. Unusually for RNA viruses, they are rather large with a genome
of about 30kb. This large size has consequences for their mutation rate
that will be discussed below. The fact that these viruses are positive
sense means that their genome is in the same sense as mRNA and the
genomic RNA may be used as an mRNA as soon as the cell has been
infected. Maturing virus particles bud
through intracellular membranes and gain a lipid envelope (i.e. coronaviruses are enveloped viruses). This has consequences for
infection control since they are likely to be less stable than
non-enveloped viruses and to be sensitive to detergents and organic
solvents. The structure of a coronavirus is shown in figure 10 and the
external morphology in figure 11.
COVID-19
Genome
SARS-CoV-2 has a genome of 29,829 bases and is
like a typical cellular mRNA (figure 12). It has a 3’ poly A tail
and is capped at the 5’ end. The latter consists of a guanine
nucleotide linked to the mRNA via an unusual 5′
to 5′ triphosphate bond. This
guanosine is methylated on the 7 position by a virus-encoded
methyltransferase. In addition, the 5’ end is methylated on the 2′
hydroxy-groups of the first two ribose residues. This cap provides
resistance to degradation by 5′
exonucleases in the cell.
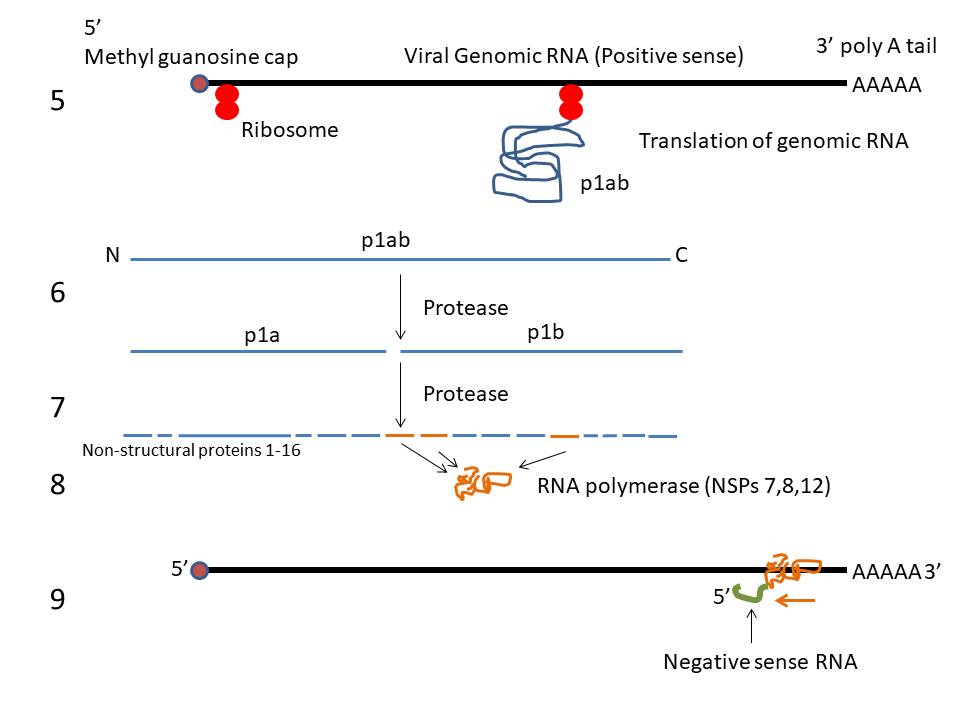
About two thirds of the genome, starting at the
5’ end, codes for non-structural protein (NSP) 1ab. This is also
known as the replicase gene although other proteins besides the
replicase (RNA polymerase) are encoded in this gene. Non-structural
proteins are virus-encoded proteins that are not part of the mature
virus particle but are used in the replication and maturation of the
virus. The coding sequences for protein 1a and 1b are not in the
same reading frame but the ribosome undergoes a -1 frame shift at
the end of the gene for protein 1a so that a long polyprotein is
made. This is then cleaved by a virus-encoded protease to proteins
1a and 1b. Proteins 1a and 1b are themselves polyproteins and are
cleaved by virally-encoded protease activity to 16 smaller
non-structural proteins. Non-structural proteins are needed before
the structural proteins since they are involved in viral RNA and
protein synthesis and thus must be made shortly after the infection
of the cell. This is done by translating incoming positive sense
genomic RNA which has all of the characteristics of a cellular mRNA.
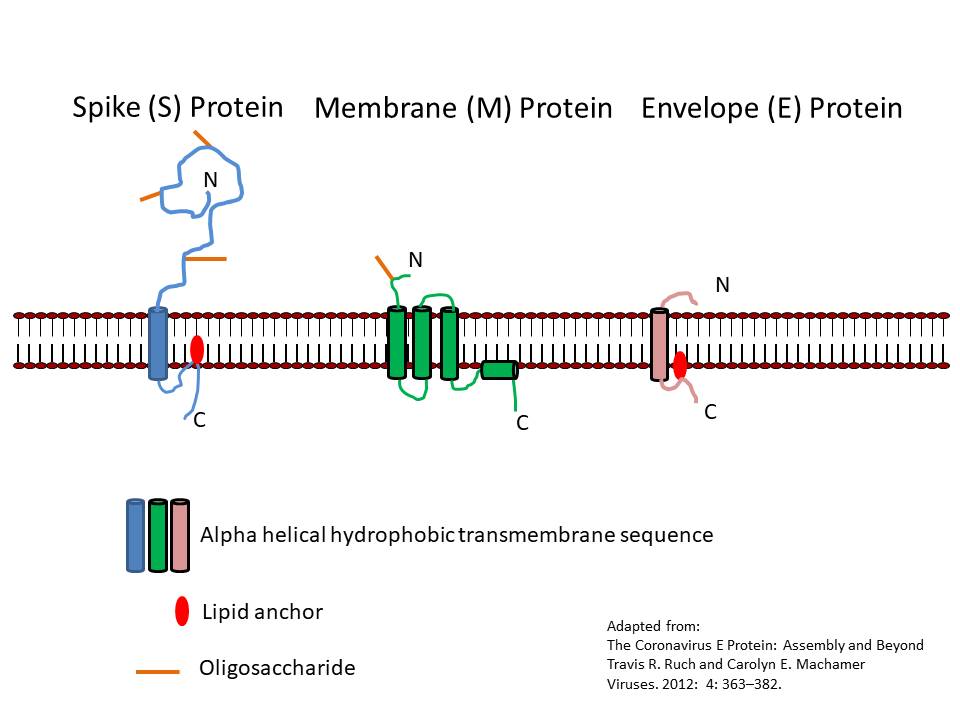
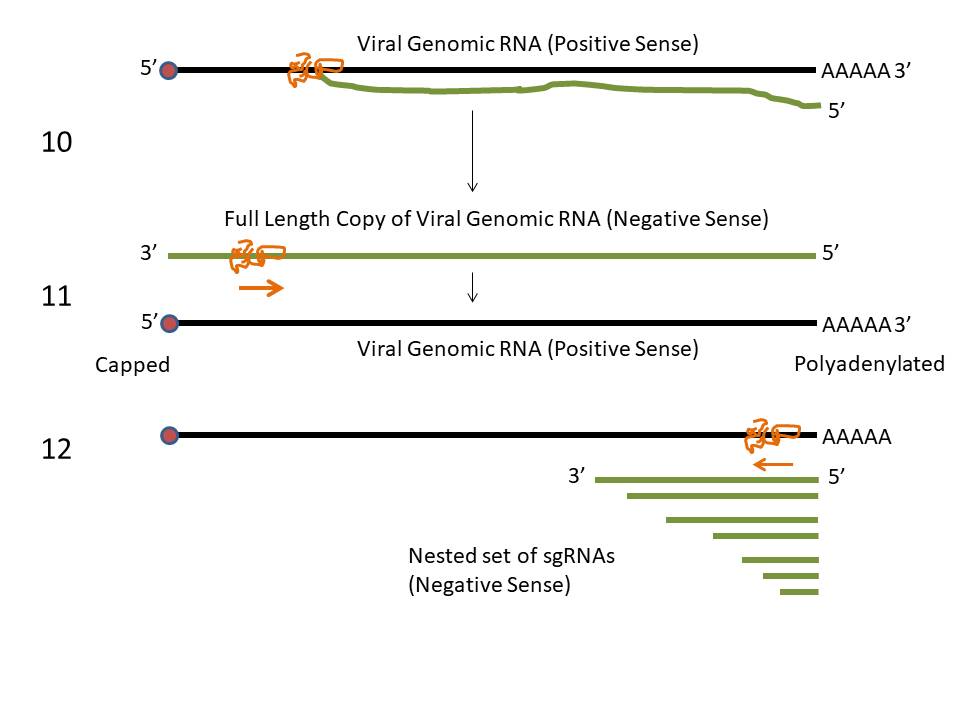
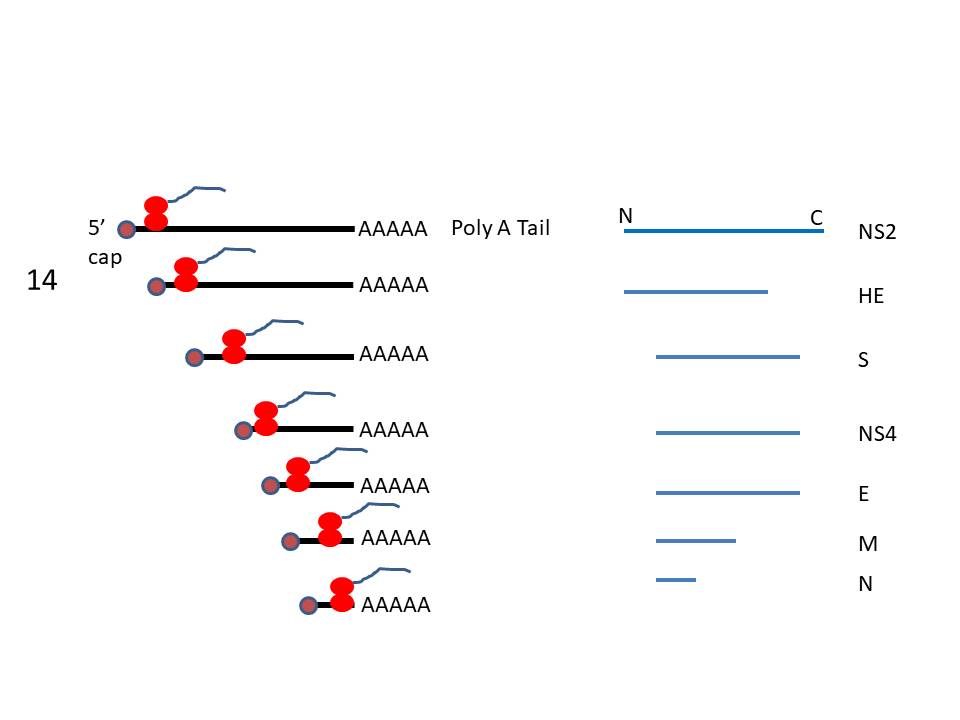
The genes for the structural proteins are
located in the the 3’ third of the genome. These are transcribed
into a set of complementary minus-strand RNAs that are templates for
the transcription of a nested set of sub-genomic mRNAs from which
the structural proteins are translated (figure 13).
In SARS CoV-1 and -2 and MERS CoV, there are
four main open reading frames in this 3’ region that code for:
In addition, there are a number of smaller
open-reading frames that code for proteins that may be structural or
serve some accessory function.
Coronavirus Proteins
The
non-structural proteins, NSP 1 – NSP16
The function of some of these proteins is
unknown but some are involved in controlling the infected cell’s
nucleic acid metabolism. In most cases this is inferred from
research on other coronaviruses such as the closely related SARS
CoV-1 and MERS CoV and is not the result of investigations of
SARS-CoV-2.
NSP1 - Reduction of
host cell protein synthesis
NSP1 very effectively shuts off host cell
protein translation by binding to the 40S ribosomal subunits. The
complex of NSP1 and the ribosomal subunit also acts as an enzyme
that inhibits host cell protein translation by means of an endonucleolytic cleavage near the 5'UTR (untranslated region) of
host mRNA leading to host cell mRNA degradation. This begs the
question of why the viral mRNAs are not cleaved in a similar manner
since, to all intents and purposes, they look just like cellular
mRNAs. It turns out that NSP1 binds to a stem-loop structure in the
5'UTR of SARS CoV-1 RNA and this interaction stabilizes the mRNA
carrying the specific stem-loop and enhances viral protein
translation.
NSP2 - A protein of
unknown function
NSP2 expressed in cells using retroviral
transduction was specifically recruited to viral replication
complexes. It is not required for viral replication in cell culture
although deletion of the NSP2 coding sequence attenuates viral
growth and RNA synthesis. Other than that, the function of NSP2 is
not known.
NSP3 - A
multifunctional protein that contains a protease
This is the largest protein encoded by the
coronavirus genome, with a size of about 200 kD. It is an essential
component of the replication/transcription complex of the virus and
spans the membrane of the endoplasmic reticulum. As might be
expected for such a large protein, it has several domains with
different functions:
A
ubiquitin-like domain 1 (Ubl1). This binds to the
single-stranded RNA and interacts with the nucleocapsid (N)
protein. It is essential for viral replication which ceases when
the UbL1 domain is partially deleted.
A
glutamic acid-rich acidic domain (also called "hypervariable
region")
A
protease (papain)-like domain (protease 1 (PLpro). This releases
NSP1, NSP2, and NSP3 from the N-terminal region of polyproteins
1a and 1ab.
A
macrodomain or X-domain. This
is not needed for
RNA replication but may be involved in counteracting the host
innate immune response.
Another ubiquitin-like domain 2 (Ubl2). The function of this is
not known.
Another protease (papain)-like domain (protease 2 (PL2pro)).
NSP3 ectodomain (3Ecto, "zinc-finger domain"). This is
the only domain located on the lumenal side of the endoplasmic
reticulum in SARS-CoV-1 NSP3. It is thought to bind metal ions
and contains an asparagine-linked oligosaccharide.
Domain Y1, the function of which is not known
CoV-Y
domain which is also of unknown function. Domains Y1 and CoV-Y
are on the cytosolic side of the endoplasmic reticulum.
There are two transmembrane domains in NSP3
which appears to cross
the endoplasmic reticulum membrane twice. These, plus the
3Ecto domain, are important for the PL2pro protease domain to cleave
the site between NSP3 and NSP4 in SARS-CoV-1. The transmembrane
domain may bring PL2pro close to the cleavage site between the
membrane-associated proteins NSP3 and NSP4.
NSP3 together with NSP4 and NSP6 are required
for the formation of the double membrane vesicles that are
characteristic of coronavirus-infected cells.
NSP4 -
Reorganization of cell membranes
NSP4 is a glycoprotein that spans the
endoplasmic reticulum membrane four times with three loop regions.
Loops 1 and 3 are exposed to the endoplasmic reticulum lumen while
loop 2 and the N and C termini are cytosolic. There are two
asparagine-linked glycosylation sites in loop 1.
As will be described below, many positive
strand RNA viruses, including coronaviruses, modify host cell
cytoplasmic membranes that are sites of viral RNA synthesis and the
formation of viral replication complexes. Coronaviruses induce
double-membrane vesicles and when infected cells are analyzed by
electron microscopy, NSP4 mutants have aberrant morphology in their
double-membrane vesicles compared to cells infected with wild type
virus. Thus, NSP4 may play a role the organization of the membrane
vesicles which are important in RNA synthesis and viral replication
although their role in these processes is unclear. A glycosylation
site on the lumenal side seems to be important in RNA synthesis.
NSP5 - A
protease
NSP5 (3CLpro, Mpro) is a protease that cleaves
other NSP proteins at 11 cleavage sites and is essential for virus
replication. NSP5 protease is also an interferon antagonist in that
it inhibits Sendai virus-induced interferon-beta production in
infected cells by targeting a protein called NF-κB essential
modulator (NEMO).
NSP6 - Reorganization
of cell membranes
NSP6 is also involved in double membrane
formation within the infected cell. It induces perinuclear vesicles
localized around the microtubule organizing center. The double
membranes are formed as part of autophagy, a cellular response to
starvation that generates autophagosomes to transport long-lived
proteins and organelles to lysosomes for degradation. Besides being
a normal cellular process under starvation conditions, autophagy can
be activated by virus infection as part of an innate defense
mechanism; however, this anti-viral mechanism is hijacked by some
positive strand RNA viruses when autophagosomes are used to
facilitate assembly of replicase proteins. NSP6 generates
autophagosomes from the ER but limits autophagosome diameter and
expansion which inhibit the ability of autophagosomes to transport
viral components to lysosomes for degradation.
NSP7 and NSP8 - A
primase
NSP7, NSP8, NSP9 and NSP10 are constituents of the RNA replication
complex of coronaviruses.
Coronaviruses encode two RNA-dependent RNA
polymerase activities. One is primer-dependent and is associated
with NSP12 (see below). The other is associated with NSP8, a 22kD
protein which is unique to coronaviruses and is capable of de
novo initiation of RNA synthesis with low fidelity from single
strand RNA templates. Thus, NSP8 has been proposed to operate as a
primase, that is it makes oligonucleotide primers that can then be
used by NSP12, the major RNA-dependent RNA polymerase. NSP7 and NSP8
form a supercomplex, a cylinder-like structure made up of eight
copies of NSP8 and held tightly together by eight copies of NSP7.
NSP9 - A protein of
unknown function
NSP9 is a single-stranded RNA-binding dimeric
protein.
NSP10 - A scaffold
protein
NSP10 is a scaffold protein with two zinc
fingers. It interacts with NSP14 and NSP16, stimulating their 3'-5'
exoribonuclease (NSP14) and 2'-O-methyltransferase (NSP16)
activities. NSP10 is required by NSP16 as a stimulatory factor to
execute the latter’s methyltransferase activity and may stabilize
the S-adenosyl methionine-binding pocket and extend the substrate
RNA-binding groove of NSP16.
NSP11 - A
protein of unknown function
The function of this protein is unknown since a
deletion in the NSP10-NSP11/12 site abolished NSP5 protease-mediated
processing but allowed production of infectious viral particles
suggesting that cleavage at the NSP10-NSP11/12 site is not needed
for viral replication in cultured cells.
NSP12 - An RNA
polymerase
This protein, the major RNA polymerase,
assembles along with NSP7 and NSP8 into a multi-subunit
RNA-synthesis complex that carries out replication and transcription
of the viral genome. NSP12 has a
unique N-terminal
extension which has been proposed to contain a
nucleotidyltransferase activity whereas replication of the viral
RNA genome is catalyzed by a polymerase domain in the
C-terminal region.
NSP13 - A helicase
NSP13 is an RNA helicase and 5′
triphosphatase that interacts with the RNA polymerase, NSP12. A
helicase is an enzyme that catalyzes the unwinding of duplex
oligonucleotides into single strands in a nucleoside triphosphate-dependent
manner. NSP12 enhances the helicase activity of NSP13 but how NSP12
increases helicase activity is unknown.
NSP14 - An exonuclease
and methyl transferase
Most RNA polymerases do not possess a “proof-reading” activity
and, as a result, the size of RNA viruses is normally limited
to about 10kb (see below). However, coronavirus genomes are the
largest of the RNA viruses with a size around 30kb. Given the
error rate of RNA polymerases due to tautomerization of the
bases, coronaviruses would seem to need some sort of
proof-reading.
NSP14, which forms a complex with NSP10, is an exoribonuclease
and its inactivation leads to a 15-fold decrease in replication
fidelity. It hydrolyzes double-stranded RNA in a 3' to 5'
direction as well as a single mismatched nucleotide at the
3'-end mimicking an erroneous replication product. The exonuclease activity is also involved in the synthesis of the
set of sub-genomic RNAs that encode the structural proteins. In
addition to its nuclease activity, NSP14 also has a
(guanine-N7)-methyltransferase activity involved in the 5’
capping of mRNAs and the genomic RNA.
NSP15 - An endonuclease
NSP15 is a hexameric endonuclease that preferentially cleaves at
uridines. It associates with the primase (NSP9) and the RNA
polymerase (NSP12). Mutations in the catalytic site reduced
sub-genomic RNA accumulation and profoundly attenuated virus
proliferation. Coronaviruses are able to avoid detection by host
innate immune sensors that recognize double stranded RNAs. NSP15
is required to evade these dsRNA sensors.
NSP16 - A methyl transferase
NSP16, in complex with NSP10, has RNA ribose 2'-O-methylation
activity. In order to mimic cellular mRNA structure, many
viruses modify the 5'-end of their RNAs. The 5’ cap is important
for RNA stability, protein translation and also viral immune
escape. In addition to NSP14 S-adenosyl-L-methionine-dependent
(guanine-N7) methyltransferase, coronaviruses have another
methyl transferase, NSP16 which is an S-adenosyl-L-methionine
(SAM)-dependent ribose 2’O-methyltransferase.
|
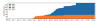 Figure 18
Figure 18
A plot of cumulative counts of D614 and G614 sequences by day in
Snohomish county. Orange represents the original form, blue the form
with the G614 mutation. 2020. King County, Washington state, USA
Tracking SARS-CoV-2 Spike mutations (lanl.gov))
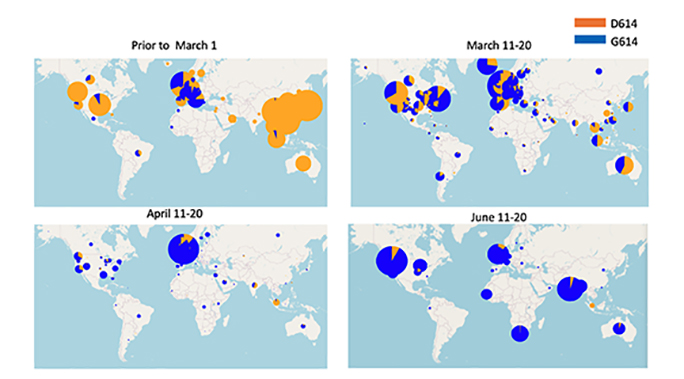
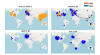 Figure 19
Figure 19
Maps showing the relative frequency of sampling D614 and G614 in
different time windows. The size of the circle indicates the relative
sampling in a given country within each of the four maps. The proportion
of the original D614 Wuhan virus is shown in orange and the proportion
of the D614G mutant is shown in blue. Top left, distribution prior to
march 11, 2020; top right, distribution March 11-20; bottom left,
distribution April 11-20; bottom left, distribution June 11-20.
Tracking SARS-CoV-2 Spike mutations (lanl.gov)
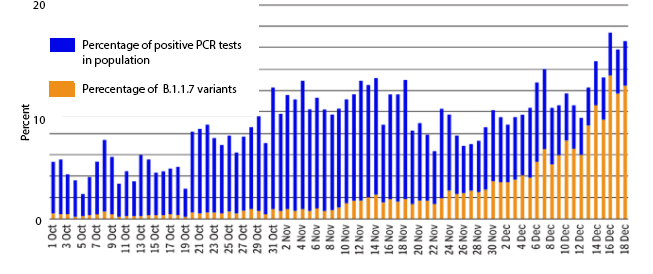
 Figure 20
Figure 20
Percentage of positive Covid-19 cases as detected from one laboratory in
the south of England between the beginning of October and mid-December,
2020. The blue bars show the percent positive tests of all tests done.
These rose from 7% to around 20% in mid-December. The orange bars show
the proportion of tests that detected the B.1.1.7 variant. The variant
was hardly present at the beginning of October whereas, by mid-December
almost all tests revealed the variant.
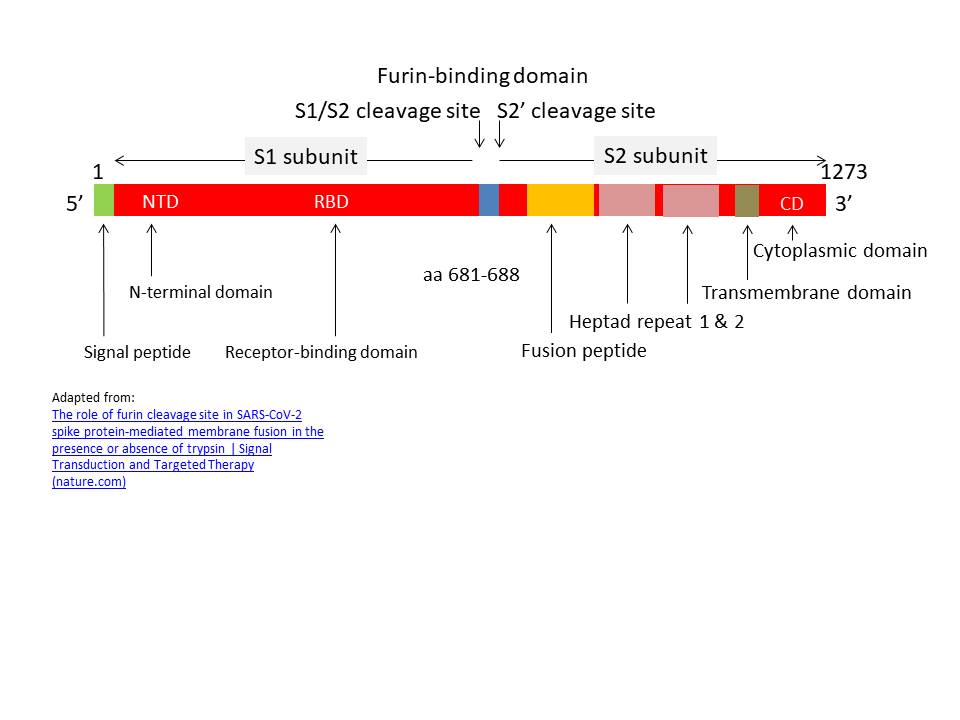
 Figure 21
Figure 21
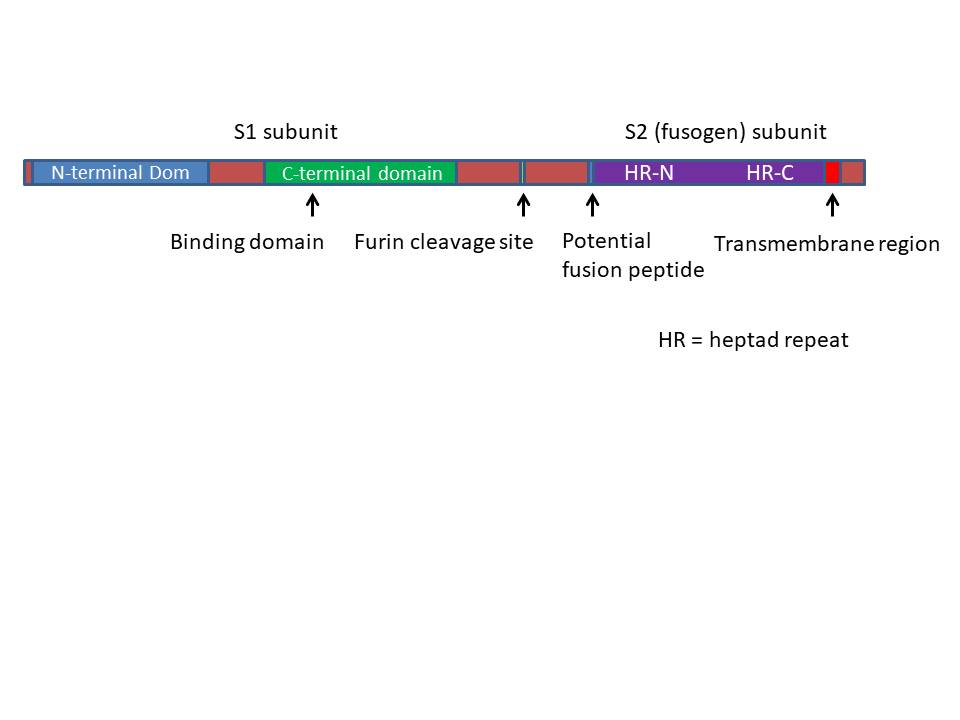
The domains of SARS CoV-2 S protein showing the Furin-cleavage sites
 Figure 22
Figure 22
The important mutations in the B.1.1.7 variant found originally on
southern England. Three are deletions and 14 are point mutations. They
are clustered in the 1a, S (spike protein), 8 and N open reading frames.
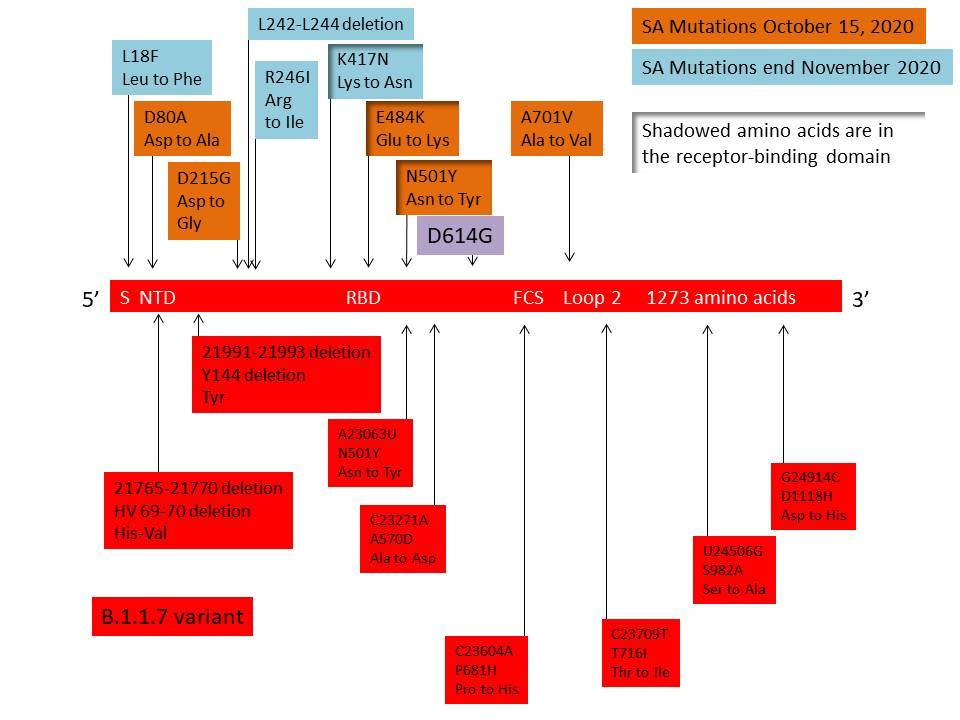
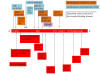 Figure 23
Figure 23
The distribution of important mutations in the S gene of the B.1.1.7
variant are shown in red in the bottom half of the figure. The mutations
in the South African variant 501Y.V2 as detected up to October 15, 2020
are shown at the top in orange. By the end of November, the variant had
acquired additional mutations shown in blue. All these variants have the
D614G mutation. Shadowed amino acids are in the receptor binding domain.
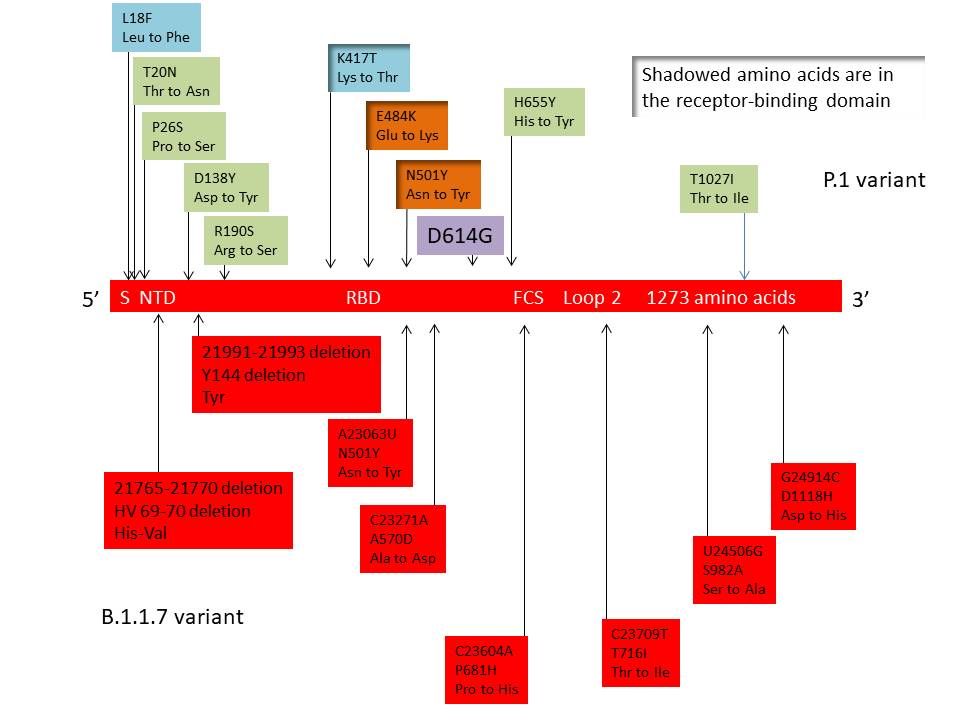
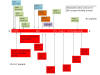 Figure 23a
Figure 23a
The distribution of important mutations in the S gene of the P.1 variant
(top) and the B.1.1.7 variant (bottom)
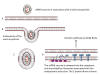
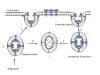
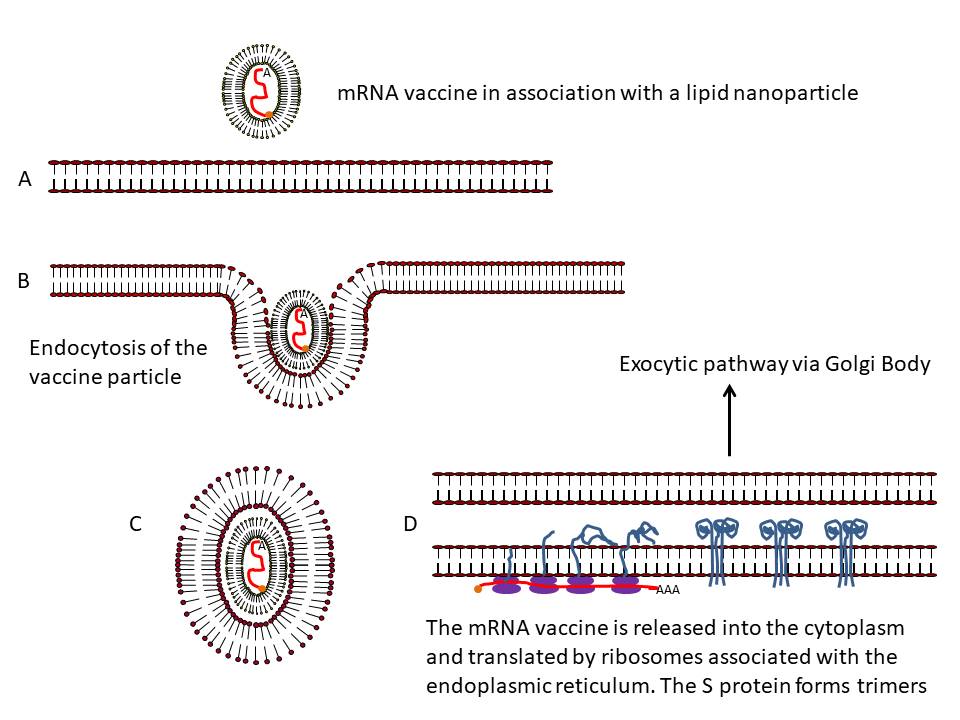
 Figure 24
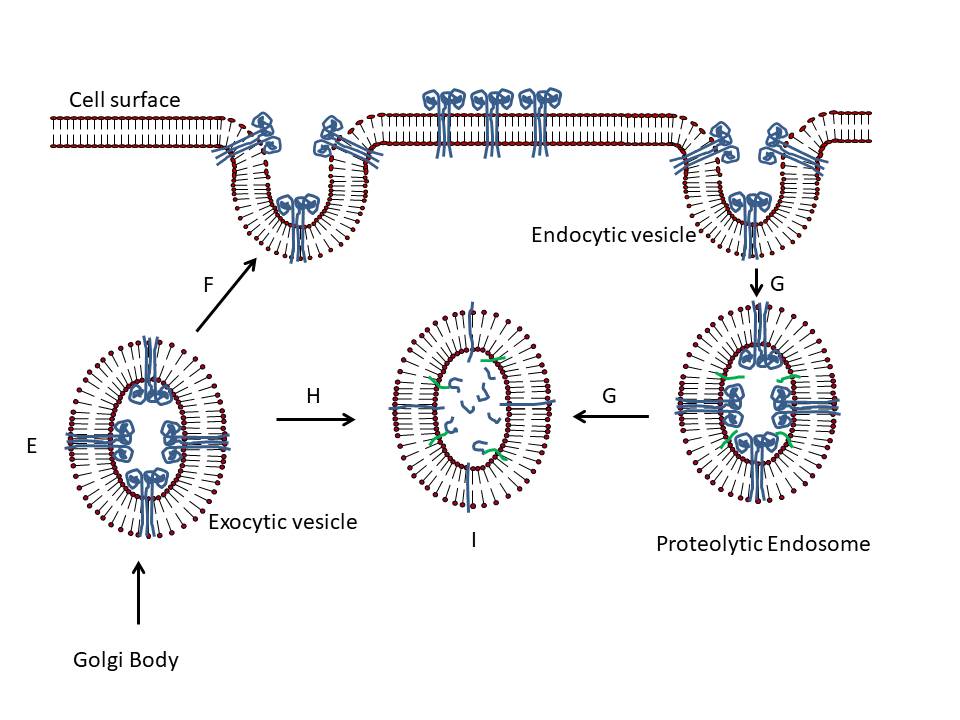
Figure 24
Presentation of S protein of SARS CoV2 to the immune system by an mRNA
vaccine
The capped and polyadenylated mRNA is encapsulated inside a lipid
nanoparticle (A) which is taken up into an endosome (B and C). The mRNA
is released into the cytoplasm and associates with ribosomes. The
translated protein contains an N-terminal signal sequence so that the
polysome associates with the signal receptor on the cytoplasmic surface
of the endoplasmic reticulum and translocates into the intra-endoplasmic
reticulum space. It acquires post-translational modifications, including
glycosylation, folds in the normal way and trimerizes (D). The S protein
follows the normal exocytic route via the Golgi Body and passes into
exosomes (E). From here, the protein may go to the cell surface (F) and
be endocytosed into a proteolytic endosome (G) or it may go directly to
a proteolytic endosome without secretion (H). The protein is degraded by
endosomal proteases and the resulting peptides bound by major
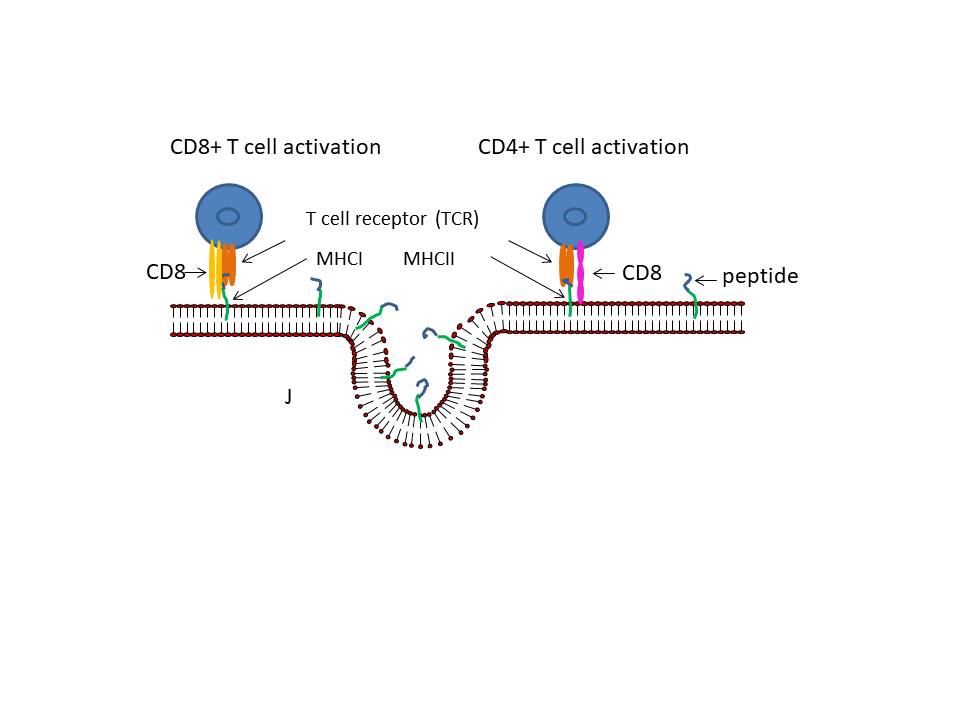
histocompatibility (MHC) antigens (I). CD4+ and CD8+ T cell activation
then occurs via the presentation of the peptides on MHC class II and
class I respectively (J).
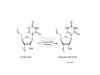 Figure 25
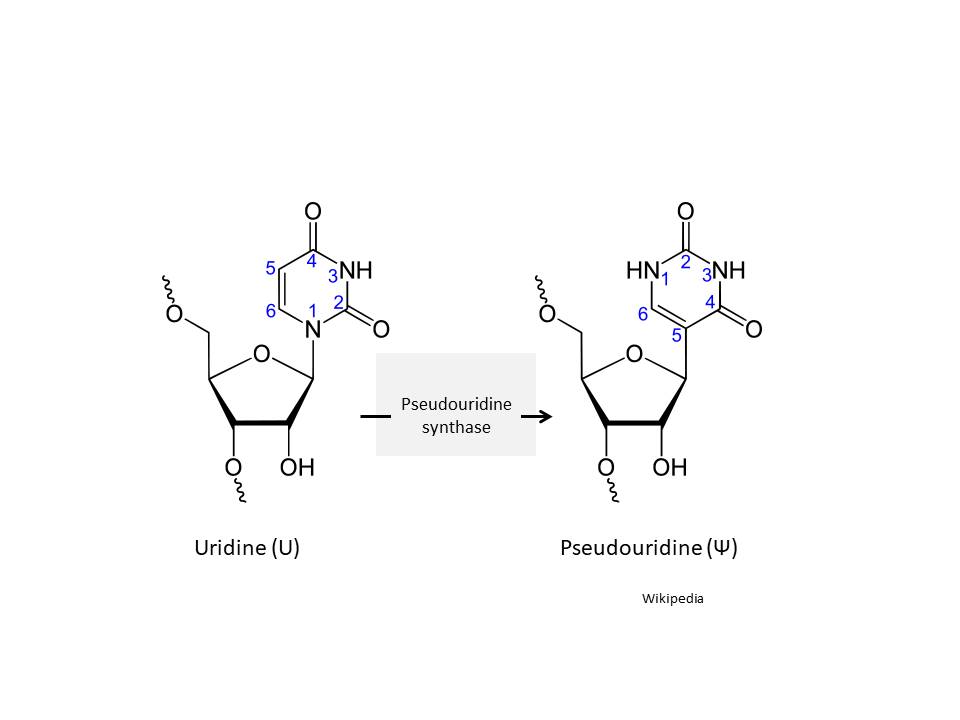
Figure 25
Pseudouridine and uridine structure
 Figure 26
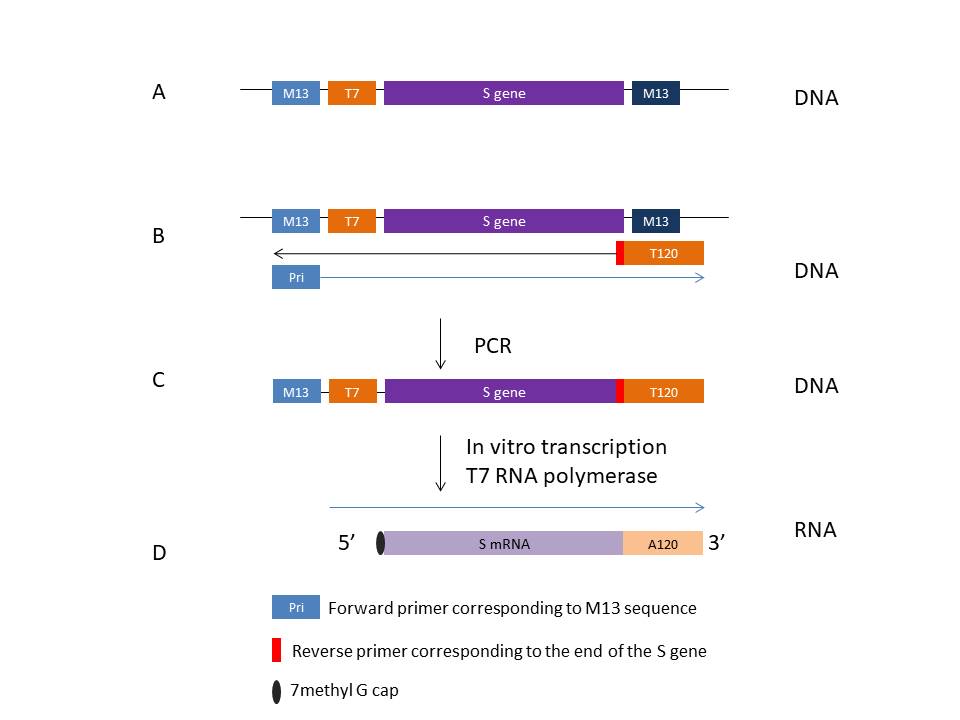
Figure 26
Transcription of an mRNA vaccine molecule from a DNA plasmid construct
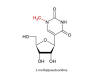 Figure 27
Figure 27
1-methylpseudouridine. An extra methyl group is added enzymatically to
the base of the pseudouracil
See also: VIROLOGY CHAPTER 8
VACCINES |
SARS COV-2 VARIANTS
SARS CoV-2 belongs to the Coronavirus family which have the largest
genome of any RNA viruses. Despite having some proof-reading capacities,
these viruses, like all RNA viruses, are subject to rapid mutation as
they replicate. Most mutations are either deleterious to the virus or
are silent (i.e. have no effect). The latter either do not alter the
amino acid sequence (they just alter the nucleotide sequence) or are
conservative mutations in which the properties of the amino acid side
chains are similar (e.g. a change from alanine to leucine or aspartic
acid to glutamic acid). However, some mutations give the variant virus a
selective advantage; these will proliferate more rapidly and will
rapidly become the dominant variant in the population.
D614G mutation
The original Wuhan virus has an aspartic acid at amino acid 614 in
the receptor binding region of the S1 subunit of the spike protein
(614D). This mutated to a more infectious form with glycine at that
position. The mutant virus (known as D614G, or just G614) increased
in frequency relative to 614D in a manner consistent with a
selective advantage. This amino acid mutation has become
increasingly common as SARS-CoV-2 viruses spread around the world.
In fact, the original G614 SARS-CoV-2 viruses differed from the
original Wuhan form by 4 mutations and almost all of the time G614
is found linked to the other 3 mutations.
The Wuhan D614 form of the virus rapidly spread around the globe in
early 2020 but where D614 and G614 co-circulated, the G614 form
usually showed a rapid increase in relative frequency and came to
dominate the population of viruses. D614G is now clearly the
dominant form of the virus globally and the transition took about
4-6 weeks (figure 18 and 19).
The question arose as to why G614 seemed to out-compete D614. This
could be due to what is known as a founder effect such as the mutant
form arising in a super spreader so that there were more of these
viruses available to infect other people. Alternatively, the mutant
form might just be more infectious (i.e. transmissible) than the
D614 form. The latter appears to be the case since the frequency of
G614 increased everywhere throughout March 2020, including in many
areas where G614 appeared in well-established local D614 epidemics.
An in-depth investigation of transmissibility in the United Kingdom
found that G614 increased in frequency relative to D614 in a manner
consistent with a selective advantage in the virus.
UK Variant B.1.1.7 - December
2020 Variants arise all the time as the virus mutates
but in December 2020 a variant, called B.1.1.7 was identified that
appeared more often in samples in the south of England, although
this variant had in fact been circulating for some months. When
compared to the Wuhan virus, this variant contains 23 mutations.
Some are silent but some could affect the interaction of the virus S
protein with the cell ACE2 receptor. This variant displaced other
variants as it spread across southern England, suggesting that it is
more easily transmissible (more than D614G which was itself more
transmissible than the original Wuhan virus) although other
explanations of the displacement are possible. It is estimated that
B.1.1.7 has an increased transmission rate of 50 to 70 percent
compared with other variants. Although the variant spreads more
rapidly, there is no evidence that it causes more severe disease or
that it will not be susceptible to vaccines that originally targeted
D617G.
The S protein consists of 1273 amino acids. In the Golgi Body it is
cleaved by a protease called Furin into the S1 and S2 subunits.
There are two Furin cleavage sites and a small part of the protein
is lost. The S1 subunit contains the N-terminal signal peptide and
the receptor binding domain. The S2 subunit contains the fusion
sequence that allows the viral envelope to fuse with the cell
membrane, the transmembrane domain and the cytoplasmic domain
(figure 21).
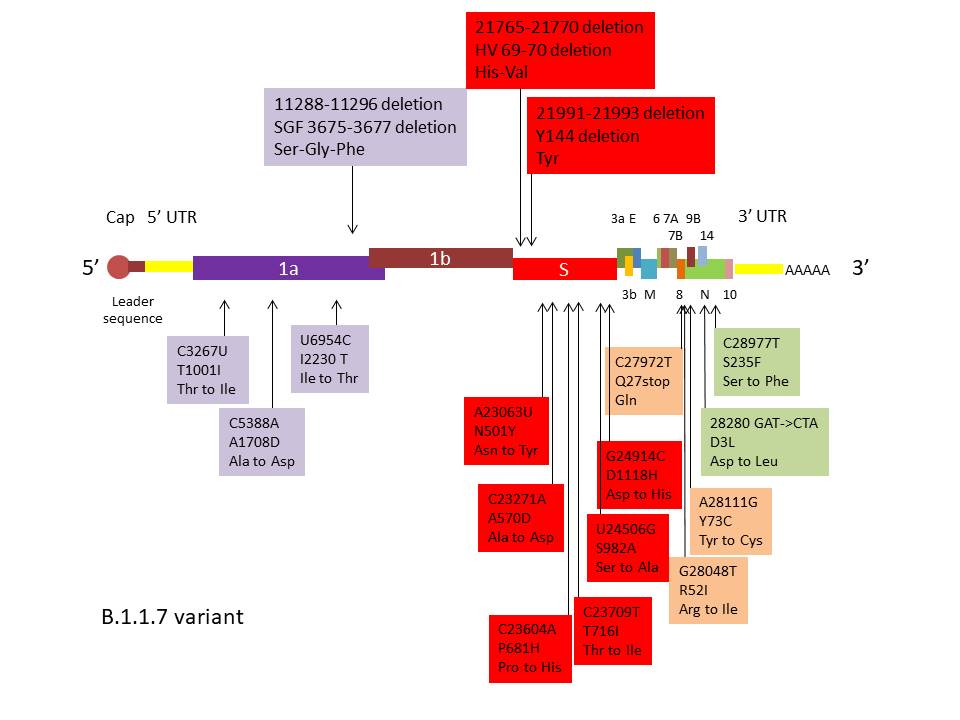
B.1.1.7 has 23 non-synonymous mutations (mutations that cause an
amino acid change or stop protein synthesis). Figure 22 shows the
mutations of importance in the variant. Eight of these mutations are
in the S protein gene including two small deletions. Two are in the
receptor binding domain of the S protein; these are N501Y which
causes a change from Asn to Tyr (both neutral polar amino acids
though the side chain of Tyr is larger) and A570D in which the
change is Ala to Asp. This is a non-conservative change in which a
neutral polar amino acid is replaced by an acidic polar amino acid.
This mutation might be the basis of the greater transmissibility of
the variant as it may alter the S protein - receptor interaction.
Three mutations are in ORF (open reading frame) 8, one of which is a
stop mutation leading to an inactive truncated protein. However, the
ORF8 deletion has only a small effect on virus replication compared
to viruses without the deletion. By late December, 2020 this
variant was identified in several counties in Europe and in the
United States. Neither of the first two variant-positive Americans
had traveled internationally in recent weeks.
South African Variant 501Y.V2
At the same time as B.1.1.7 was emerging as the dominant, more
transmissible variant in southern England, another more
transmissible variant was arising in South Africa. This is known as
501Y.V2 and has eight lineage-defining mutations in the spike
protein, including three at important amino acids in the
receptor-binding domain that may have functional importance. These
mutations are shown is figure 23 where they are compared with those
in B.1.1.7. The three important mutations in 501Y.V2 are K417N (Lys
to Asn, basic to neutral polar), E484K (Glu to Lys, an acidic to
basic change) and N501Y (Asn to Tyr, both neutral polar amino
acids). The N501Y mutation is also seen in the S protein gene of
B.1.1.7 and is part of the binding loop in the contact region with
human ACE2 where it forms a hydrogen bond with ACE2 tyrosine 41. It
also interacts with lysine 353 in the virus-binding region of ACE2
and may enhance the binding affinity of SARS-CoV-2 for human ACE2.
There is some evidence that the E484K mutation may also modestly
increase receptor binding affinity but the K417N mutation has little
effect on the binding affinity to ACE2.
The variant, as might be expected, accumulated more mutations
over time. On 15 October, the South African variant had, in addition
to D614G, five other non-synonymous mutations in the spike protein:
D80A, D215G, E484K, N501Y and A701V. Three additional spike
mutations emerged by the end of November: L18F, R246I and K417N
(figure 23).
Alterations in the B.1.1.7
variant - January 2021 The original B.1.1.7 does not
contain the escape mutation (E484K) that makes the South African
variant more resistant to vaccines. E484K makes it more difficult
for antibodies to attach to the virus and prevent it from entering
cells. In late January, 2021 some B.1.1.7 variants in Britain seem
to have acquired the E484K mutation.
P.1 (B1.1.248) variant
In April 2020, Manaus, a city in
the Brazilian Amazon, experienced a severe first wave of SARS-CoV-2
infections but the population resisted lockdowns and social
distancing was not enforced. As a result, so many people were
infected (76% of the population) that it was thought that the city
could have reached herd immunity since they were assumed to have
protection against the virus. As a result of herd immunity resulting
from three quarters of the population being infected in the initial
wave of the virus, it was expected that there would not be a great
spread of the virus in a second wave in which the Rt number would be
lower than 1. However, in January 2021, Manaus suffered a second
wave of COVID-19 infections that overwhelmed its hospitals leaving
oxygen supplies exhausted and dozens of people to die in their homes
and intensive care hospitals. Sequencing showed that a new variant
of SARS-CoV-2, known as P.1, accounted for about half of new
infections. P.1 was also found in a few cases in Japan among people
who have recently traveled from Manaus. Like some other variants
such as those first identified in the UK and South Africa, P.1
appears to be more transmissible that the original D614G virus that
spread across the world, raising concerns about a greater risk of
spread. The virus has 17 unique amino acid changes, 3 deletions, and
4 synonymous mutations, plus one 4 nucleotide insertion compared to
the most closely related viruses. As with other variants, mutations
in the S protein receptor binding site are those that give rise to
most concern. These are K417N, E484K and N501Y (figure 23a). In the
case of the lysine at position 417, there is a change to Asn in the
South African variant and to Thr in the P.1 variant. N501Y is found
in both the UK and South African variant and changes at 417 and 484
are also in the South African variant. By late January 2021, the P.1
variant had spread as far as Japan, Germany and the United States.
So why the second surge in infections? Could it be that P.1 is not
recognized by antibodies in people who were infected during the
first wave of infection? It may be that people thought to be immune
because of a previous infection had become reinfected suggesting
that the immunity they developed during the first wave was not able
to suppress the new variant. This is very concerning for vaccine
efficacy. Nevertheless, we do not know (January 2021) whether people
are being reinfected or whether the more highly transmissible virus
is spreading through the remaining quarter of the population since,
as of late January, 2021, there had only been one confirmed case of
reinfection; it could be that the increased transmissibility raised
the Rt and hence the threshold for the onset of herd immunity.
Besides making the virus more transmissible, it does appear that
P.1 mutations decrease the immune system’s ability to recognize and
neutralize the virus. This seems also to be the case with the South
African variant that is so similar to P.1 at three important sites
in the S protein. Studies on whether the South African variant could
be neutralized by antibodies from patients infected with older
versions of SARS-CoV-2 showed that in about half of cases the new
variant was resistant to neutralization by the plasma serum;
however. it should be noted that while P.1, like the other recent
variants, is more highly transmissible, there is no current evidence
that it causes more severe disease.
Mutations in P.1 (figure 23a)
N501
The mutation at N501 allows the virus S protein to bind more
easily to the ACE2 receptor on the cell surface. This makes the
virus more infections (up to 70% more infectious in some
studies).
E484
The mutation in P.1 at amino acid 484 (Glu to Lys) is more
worrisome. It has been referred to as the escape mutation and is
also in the South African but not the UK variant. It seems to
allow the virus to escape at least partially the antibodies
generated in a previous non-P.1 infection and also possibly the
antibodies in the therapeutic monoclonal antibody cocktails made
by companies such as Regeneron. Of much more concern is that
this mutation may allow the virus to escape antibodies generated
by the current vaccines which would require the alteration of
the DNA sequences used to generate those vaccines. It is
probable that the vaccine will work against the new variants
avoiding serious COVID-19 disease which may be replaced by
milder symptoms.
K417
Both P.1 and the South African variants have a mutation at amino
acid 417, although the altered amino acid differs in the two
variants (Thr in P.1 and Asn in the South African variant). That
mutations at this point should have risen independently suggest
that it confers some advantage on the virus but its significance
is unknown.
P.2 variant On
12 January 2021, researchers in Brazil reported on the detection of
a variant of the P.1 lineage that, like the P.1 variant, has the
E484K mutation. It probably evolved independently of the P.1
variant.
Are these variants neutralized
by the current vaccines? So far, the answer seems to be yes,
although the South African variant may be less susceptible to both
the antibodies produced in a natural infection and by the first
vaccines but at least they should prevent serious illness.
Co-infections Two
COVID-19 cases have been discovered in Brazil in people in their
mid-30s who were infected with both the P.2 variant and a different
strain circulating in Brazil. It is possible that these
co-infections could lead to the creation of additional hybrid
variants.
COVID-19 VACCINES
Until the Covid pandemic, all successful vaccines had been based on
attenuated viruses, killed viral particles or purified proteins (subunit
vaccines). These present viral proteins with or without the viral
context to the immune system. They require a lot of development, take
time to produce in large quantities, require substantial purification
and usually do not present the antigen to the immune system in the same
way as a natural infection resulting in a virus-infected cell. Until
December 2020, no vaccine for human use had been approved that was based
on injecting nucleic acids even though these vaccines are easier to
produce in large quantities and can be rapidly tailored to changes in
the circulating virus using molecular biology techniques.
Nucleic acid-based vaccines can be either DNA or RNA. DNA vaccines
consist of the appropriate gene inserted into a viral vector that can be
taken up by the cell, transcribed to mRNA and translated into protein.
RNA vaccines omit the first stage and directly insert translatable mRNA
into the cytoplasm of the cell. Both types of vaccine cause the cell to
produce and process viral protein or proteins in the same way as occurs
in a natural infection. The surface protein encoded by the nucleic acid
passes through the cells’ export pathway acquiring the
post-translational modifications that also occur in the natural
infection. The antigen may also be passed through the proteosomal or
proteolytic endosomal pathways resulting in peptides that can be
presented at the cell surface is association with class I and class II
histocompatibility antigens and so mediate a strong cell-mediated immune
response as well as an antibody-mediated response.
MRNA VACCINES
The
first two vaccines approved in late 2020 are based on a protocol in
which mRNA coding for the antigen of interest surrounded by a lipid
carrier (lipid nanoparticle) is injected into the vacinee. The lipid
protects the mRNA from ribonucleases and facilitates its entry into
cells. The mRNA is translated to protein, processed and presented to the
immune system in the usual way. The protein of interest is usually that
which binds to the cell receptor and antibodies to this protein which
block virus-cell receptor interaction will prevent infection and are
called neutralizing antibodies. In the case of vaccines against
SARS-CoV-2, this is the S antigen that binds to the human ACE2 receptor.
A major problem with mRNA vaccines is their stability in transit from
the site of manufacture, outside the cell at the site of injection and
within the cell. DNA Is inherently stable within the cell since it must
pass the genetic code from cell to cell indefinitely. In contrast, mRNAs
have a very short life compared to DNA. The amount of a mRNA depends on
the balance between the rate of synthesis and the rate of degradation.
Many proteins are required only for a very short time, and if their
mRNAs were very stable the protein level could not be controlled. Hence,
although all mRNAs have short lives, many are degraded very rapidly
after translation, facilitating rapid responses to the conditions in the
cell. The mRNAs are degraded by ribonucleases (RNAses). Different mRNAs
have different degrees of stability resulting from their secondary
structure and the nature of the ends of molecule. These are known as cis
elements. In addition, their stability is also regulated by RNA-binding
factors or trans elements. Cis elements include the 3’ poly A tail and
the 5’ methyl guanosine cap. The 3’ poly A tail is bound by poly
A-binding proteins that stabilize the RNA. These proteins require a
certain length of poly A tail to bind and so the longer the poly A tail,
the more of these proteins can bind to the RNA. mRNA is degraded from
the 3’ end by 3’-5’ exonucleases and the 5’ end by removal of the 5’ cap
and 5’-3’ exonuclease activity. Endonuclease activity also degrades mRNA
and this can be regulated by other RNA binding proteins. AU-rich
sequences in the 3’ untranslated region (UTR) are also involved in
stability.
MRNA may also be stabilized by chemical modification of the bases of
the nucleic acid itself. Such modifications include methyl adenosine,
N-1-methylpseudouridine and pseudouridine (made from uridine by
pseudouridine synthase (figure 25)), a base modification that is common
in tRNA and enhances its stability. In mRNA these substituted bases
enhance translation. Pseudouridine and N-1-methylpseudouridine repress
intracellular signaling triggers for protein kinase R activation which
is involved in mRNA stability. Of course, such modifications must not
alter the fidelity of the translation of the message. MRNA vaccines
are made by the transcription of a plasmid encoding a protein recognized
by a neutralizing antibody, in the case of a Covid-19 vaccine, this is
the S protein. The plasmid, which contains the appropriate promoter
sequences, is linearized and transcribed in vitro using a T7, T3 or Sp6
phage RNA polymerase. The resulting product contains an open reading
frame that encodes the S protein flanked by 5’ and 3’ UTRs, a 5’ methyl
guanosine cap and a poly A tail. This is what is used as the vaccine.
Figure 26 shows one way that this might be done in a system from AmpTec.
The S protein gene is cloned into an insertion site in an m13 plasmid
along with a T7 promotor (A). A forward primer complementary to the end
of the M13 sequence (Pri) and a second reverse primer complementary to
the end of the S gene are used (B). The latter primer includes a poly T
sequence, usually around 120 nucleotides which does not hybridize to any
m13 sequence. Using PCR, the DNA structure shown in C is produced. This
is then used in in vitro transcription from the T7 promoter to form the
polyadenylated mRNA shown in D. In vitro transcription can be carried
out in the presence of modified nucleotides such as pseudouracil and/or
N6-methyl adenosine, 5-methyl cytidine and others. These modified mRNAs
are much more stable than normal mRNAs and are highly translatable
giving the vaccine much increased efficacy.
The resultant protein is processed in the normal way through the
exocytic pathway with all the usual post-translational modifications
including glycosylation and transported to the cell surface. As
described above, the protein may also be cleaved by proteases to form
small peptides that can be presented at the cell surface to the immune
system. The cell has anti-viral mechanisms to detect and degrade foreign
RNAs and steps are taken to minimize this.
Even with nucleotide modifications, naked mRNA is likely to be
rapidly degraded when injected into the vaccinee. In addition, the mRNA
must cross the cell membrane to gain access to the cell protein
translation machinery. Both of these problems can be solved by
encapsulating the mRNA in a lipid envelope (a lipid nanoparticle or
liposome) that helps the mRNA vaccine enter the cytoplasm from the
endosome before it is degraded in a lysosome.
The initial Covid mRNA vaccines from BioNtec and Moderna use a
technology similar to the above. A modification that may well be used in
future mRNA vaccines is to make an mRNA vaccine which contains not only
mRNA for the protein of choice (e.g. the SARS-CoV-2 S protein) but also
mRNA for a viral RNA-dependent RNA polymerase (replicase). When this
type of mRNA vaccine is injected into a vaccinee and enters a cell, it
will be translated into S protein and into the replicase (which may be
encoded on the same mRNA or a second mRNA). The viral replicase can
recognize viral replication signals included in the vaccine mRNA(s) and
can then amplify the input vaccine mRNA, making more copies of the mRNA
and therefore more of the protein. Since there is now more of the
vaccine mRNA in the cell than was originally delivered to the cytoplasm,
this is known as the self-amplifying (SA) mRNA approach.
Tozinameran (BNT162B2.
Brand name: Comirnaty) Pfizer-BioNTech Covid-19 vaccine
Tozinameran was the first mRNA vaccine to be approved. In clinical
trials its efficacy is around 95%, 28 days after the first dose and
is well tolerated. In one of the initial trials, there were 170
confirmed cases of Covid-19 of which 162 were in the placebo group
and only 8 in the vaccine group. It is given in two doses, three
weeks apart. It was not evaluated for asymptomatic infection. It
appears to be effective against the variants described above. This
vaccine must be stored and transported at -70 C. It contains (WHO
Non-proprietary names Program):
A modified 5’-cap1 structure (m7G+m3'-5'-ppp-5'-Am)
5´-untranslated region derived from human alpha-globin RNA with
an optimized Kozak sequence. The latter ensures that the protein
is correctly translated by the ribosome and functions as the
translation initiation site in most eukaryotic mRNAs.
S glycoprotein signal peptide necessary for directing the
nascent protein/ribosome complex to the signal receptor on the
cytoplasmic surface of the rough endoplasmic reticulum membrane.
This guides protein translocation to the correct orientation in
the endoplasmic reticulum.
Codon-optimized sequence encoding full-length SARS-CoV2 S
protein that contains two mutations: K986P and V987P. These
alter the folding of the S protein so that it adopts an
antigenically optimal pre-fusion conformation. All of the
uridines are replaced by 1- methyl-3’-pseudouridine residues (Ψ)
(figure 27) that are nevertheless efficiently translated.
At the end of the coding sequence are two ΨGA stop codons
The 3´ untranslated region comprises two sequence elements that
confer RNA stability and high protein expression.
A 110-nucleotide poly A-tail consisting of a stretch of 30
adenosine residues, followed by a 10-nucleotide linker sequence
and another 70 adenosine residues.
In addition the vaccine contains lipids that make up the solid
lipid nanoparticles that encapsulate the mRNA (ALC-0315 =
((4-hydroxybutyl)azanediyl)bis(hexane-6,1-diyl)bis(2-hexyldecanoate);
ALC-0159 = 2-[(polyethylene glycol)-2000]-N,N-ditetradecylacetamide;
1,2-Distearoyl-sn-glycero-3-phosphocholine; and cholesterol. In
addition, the vaccine contains water, sucrose, dibasic sodium
phosphate dehydrate, monobasic potassium phosphate, potassium
chloride and sodium chloride.
Moderna Vaccine. mRNA1273
The Moderna vaccine is also an mRNA consisting of a synthetic
message encoding the pre-fusion stabilized spike glycoprotein of
SARS-CoV-2 virus. Pre-fusion stabilization is achieved by the
substitution of two prolines as in the BioNTech vaccine. Again,
the mRNA is made by transcription from a T7 promotor in a reaction
in which UTP was substituted with 1-methylpseudoUTP. In addition to
the mRNA, the vaccine contains lipids to form a lipid nanoparticle:
(SM-102, 1,2-dimyristoyl-rac-glycero3-methoxypolyethylene
glycol-2000 [PEG2000-DMG], cholesterol, and
1,2-distearoyl-snglycero-3-phosphocholine) and, tromethamine,
tromethamine hydrochloride, acetic acid, sodium acetate, sucrose and
water. The efficacy of m1273 is around 94.1%, similar to the BioNTec vaccine.
In an initial trial, there were 196 confirmed cases of Covid-19 of
which 185 were in the placebo group and 11 in the vaccine group. It has the advantage over the latter in that the
different lipid nanoparticle formulation allows it to be stored and
transported at 2-8C, rather than the -70C of the BioNTec vaccine. It
is administered in two doses, three weeks apart.
ADENOVIRUS-BASED DNA VACCINES
AstraZenica/Oxford University
Vaccine: AZD1222, CHADOX1 NCOV-19
The ChAdOx1 nCoV-19 vaccine (AZD1222) consists of the
replication-deficient simian adenovirus vector ChAdOx1, containing
the full-length S glycoprotein gene of SARS-CoV-2, with a tissue
plasminogen activator leader sequence. ChAdOx1 nCoV-19 expresses a
codon-optimized coding sequence for the S protein. A simian
adenovirus rather than a human one is used because the use of human
adenovirus is limited by pre-existing immunity to the virus within
the human population that significantly reduces the immunogenicity
of vaccines based on the human virus. This is not a problem with the
simian virus because, although simian adenoviruses are closely
related to human adenoviruses, the hypervariable regions of the main
immunogen are significantly different from the human virus thus
avoiding preexisting immunity. The simian adenovirus vectors lack
the E1 region encoding viral transactivator proteins which are
essential for virus replication and the E3 region encoding
immunomodulatory proteins. The latter deletion allows incorporation
of larger genetic sequences into the viral vector. The vaccine
adenovirus is taken up by cells and is transcribed in the nucleus to
give mRNA which is translated to S protein. Efficacy is up to 90%,
depending on the dosage. Higher efficacy was found in a subgroup in
which the first of two doses was halved. The average efficacy was
70.4%.
AD5-NCOV, Convidicea (Cansino
Biologics, China) This is another adenovirus-based
vaccine. It is based on recombinant replication-defective human
adenovirus type-5 vector to induce an immune response. Again, the
virus has been rendered replication-deficient by deletion of the E1
and E3 genes. It encodes an optimized full-length S protein gene
based on Wuhan-Hu-1 virus sequence with the tissue plasminogen
activator signal peptide gene.
GAM-COVID-VAC, Sputnick V (Gamaleya
Research Institute of Epidemiology and Microbiology, Russia) Gam-COVID-Vac is a two-vector vaccine based on two modified human
adenoviruses containing the gene that encodes the S protein of
SARS-CoV-2. The first inoculation uses adenovirus 26 (Ad26) as the
vector for the S protein gene while the second uses adenovirus 5
(Ad5). This vaccine was shown in January, 2021, to have 91.6%
efficacy against symptomatic Covid-19. AD26.COV2.S, JNJ-78436735
(Janssen/Johnson and Johnson, United States and Belgium)
This vaccine is based again on a recombinant modified adenovirus
vector. Like the Sputnick vaccine, it uses human Ad26 expressing the
S protein, in this case in a single inoculation. It raises a strong
neutralizing antibody and cell-mediated response. It uses AdVac
technology which increases stability so that the vaccine may be
stored at refrigerator temperatures for at least three months.
SUBUNIT VACCINES
NVX-CoV2373, Novavax
The Novavax vaccine (NVX-CoV2373) is based on older technology using
purified SARS-CoV-2 S protein with a Matrix M adjuvant.
In clinical trials, it produced high levels of anti-S protein
antibodies and has been ordered by several governments as part of
their anti-Covid-19 strategy. The gene for the S protein is inserted
into a baculovirus. The Baculoviridae are a family of
double-stranded circular DNA (80-180 base pairs) viruses that infect
insects and arthropods. The modified baculovirus is then use to
infect insect cells (usually Sf9 cells, isolated from Spodoptera
frugiperda, the fall army worm) which make the S protein. This
assembles into native trimers on the surface of the infected cell.
These proteins are extracted and associated with lipid nanoparticles
so that the S protein is presented to the immune system in a manner
similar to that on the surface of an infected cell. Included with
the vaccine is an adjuvant extracted from Quillaja saponaria,
the soap bark tree (which, as its name implies can be used as a
soap). In the case of vaccines, it stimulates the attraction of
immune cells to the site of the injection where they respond more
effectively. The adjuvant properties come from saponins (triterpene
glycosides). The nanoparticles containing the S protein are taken up
by antigen-presenting cells, cleaved into peptides and presented on
the cell surface in association with MHC antigens to T and B cells.
Phase 3 trials have shown that this vaccine has 89% efficacy against
Covid-19 and appears to provide strong immunity against the UK and
South African variants.
INACTIVATED VIRUS
PARTICLES
Valneva vaccine (VLA 2001)
This uses an even more established vaccine technology similar to
that used in the Salk polio vaccine, that is the use of inactivated
whole virus particles. Virus is grown on African Green Money Kidney
(Vero) cells, purified and inactivated with an agent such as
formalin. The vaccine also contains alum and CpG 1018 adjuvants. CpG
1018 is a toll-like receptor 9 (TLR9) agonist.
OTHER VACCINES
TMV-083, Pasteur Institute
This is an attenuated live virus vaccine using the
measles vaccine virus as a vector expressing the S protein antigen
of SARS-CoV-2 virus. Because of low efficacy, the development of
this vaccine has been abandoned.
There are a number of other SARS-CoV-2 vaccines in phase I and II
trials including older technologies such as formalin-inactivated
whole virus particles (Sinovac and Sinopharm).
WHY DO WE NEED TWO
INOCULATIONS? Most of the vaccines that have been developed
against SARS-CoV-2 require two inoculations. This is because of the way
that the immune system responds to a foreign pathogen such as an
infecting virus.
Initially, it is important to suppress infection by stopping the
invading pathogen entering cells and replicating. Infection by a virus
binding to its receptor on the cell surface (ACE2 in the case of
SARS-CoV-2) triggers an initial response in which plasma B lymphocytes
produce neutralizing antibodies that bind to the surface of the invading
organism thereby, in the case of SARS-CoV-2, blocking virus S protein
binding to ACE2. The initial antibody response, however, quickly
declines but some of the B cells differentiate into memory B cells that
survive for a long time and relocate to the periphery of the body. Here,
they will be more likely to encounter more antigen during a second
exposure. When this happens, they proliferate and differentiate into
more plasma B cells, which then respond to the antigen by producing more
antibodies. Memory B cells can survive for many years so that they are
able to respond to multiple exposures to the same antigen. During the
first phase of the immune response, the immune cells also secrete
cytokines that recruit other immune cells to the site of infection,
among which are CD4-positive helper and cytotoxic T cells (killer T
cells) that recognize and kill virus-infected cells. As with B cells,
some T cells differentiate into memory cells that can reactivate and
proliferate in response to new exposure to the original antigen. These
memory T cells can also remain in the body for many years (and perhaps
for a lifetime). Since only a small number of memory T cells are made
as a result of the initial exposure, a second exposure to the antigen
(infection or inoculation) is required to boost their levels. Thus, with
the mRNA SARS-CoV-2 vaccines, protection starts about 12 days after the
first inoculation and rises to about 50% effectiveness. After a second
injection three to four weeks later, the second phase of the immune
response starts, memory B and T cells increase and effectiveness rises
to around 95%.
|


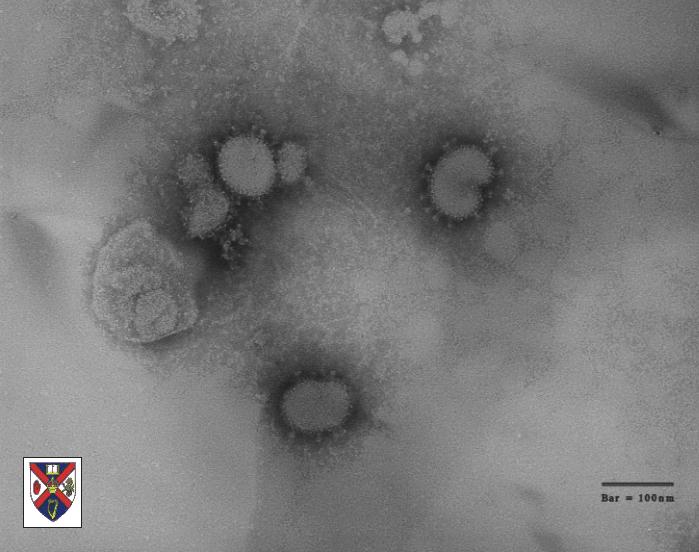 Figure 2 Torovirus
Figure 2 Torovirus
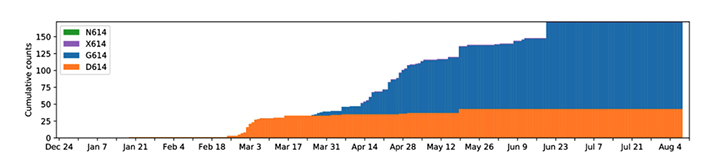 Figure 18
Figure 18